
Origami. Deployable structures
Origami. Estructuras desplegables
Paula Álvarez-García, Manuel Domínguez (1)
Abstract
Deployable structures have been extensively researched in fields such as medicine and aerospace engineering. Its application to the terrain of the architecture is, in comparison, anecdotal, linked to ephemeral constructions, roof design systems and construction supplies. This article makes a study among the different available methods to generate this kind of reconfigurable structures, the origami code. It gathers among his followers’ great mathematicians who share their theoretical research in computer programs code. Their revolutionary speculations are opposed to build architectures examples, less technologically transcendental at the present time. Finally, possible investigation lines based on the lack of theoretical novelties application to the architectural project and in the lack of classificatory studies that define action methods in the case of the application of the origami code to the architecture role are raised.
Keywords: Origami, structures, deployable, architecture.
Resumen
Las estructuras desplegables han sido ampliamente investigadas en campos como el de la medicina y la ingeniería aeroespacial. Su aplicación en el terreno de la arquitectura es, en comparación, anecdótica, ligada a construcciones de carácter efímero, al diseño de cubiertas y de sistemas de apoyo a la construcción. El presente artículo estudia entre los distintos métodos para la generación de estructuras reconfigurables el código origami. Este reúne entre sus seguidores, a grandes matemáticos que comparten sus investigaciones teóricas en forma de programas computacionales. Sus especulaciones de carácter revolucionario se contraponen a una serie de ejemplos de arquitecturas construidas, menos trascendentales tecnológicamente para el momento actual. Se plantean, finalmente, posibles líneas de investigación basadas en la escasa aplicación de las novedades teóricas al mundo del proyecto arquitectónico y en la falta de estudios clasificatorios que definan métodos de actuación ante casos de aplicación del código origami a la arquitectura.
Palabras clave: Origami, estructuras, desplegables, arquitectura.
Recibido / received: 07/11/2022. Aceptado / accepted: 03/01/2023.
(1) Design Engineering. Universidad Nacional de Educación a Distancia – UNED, Spain.
Autor para correspondencia (corresponding author): pa*********@*********ed.es (P. Álvarez)
ORCID: http://orcid.org/0000-0002-4748-0588 (P. Álvarez); http://orcid.org/0000-0003-1037-0542 (M. Domínguez)
Introduction
We call deployable those transformable structures whose shape can be modified with the addition of energy, passing from a compact state to an expanded one.
Its development takes place within the framework of the Industrial Revolution and certain avant-garde movements such as Italian Futurism that focus on technological progress. It is also worth mentioning, as a key milestone in the activation of the public interest in these structures, the theory of relativity, which presents the dimension time as geometric (RivasAdrover, 2015).
Its use has been indispensable in the aerospace field, given the facilities they offer when transporting large pieces occupying a much smaller volume until the moment of deployment. Robotics and medicine, on the other hand, benefit from this system using millimeter scales. But also, art, design and architecture draw on the dynamic possibilities of reconfigurable structures.
In the field of architecture, deployable structures have traditionally been used in specific sectors:
a) Ephemeral architectures: constructions that limit a space for a short period of time, to be later moved or reused in new contexts. This is the case of travelling exhibitions, fairs, temporary shelters, or field hospitals.
b) Roofs: for specific use and variable depending on the weather. Roofs of sports stadiums or urban squares.
c) Construction support systems such as scaffolding and formwork.
Development and methodology
The research method used to write this article is theoretical. Searches have been made for information about the topic to be developed first from a more general point of view and then from a more specific one. The progress shown in the exposition of matter has its origin in the research itself. Chronologically, articles from different periods have been selected to help to understand the concept from its origins to the present moment. The investigation process is explained below:
a) Search for scientific articles and reference books through the following databases:
• Google Scholar.
• IEE Xplore.
b) Moreover, these documents refer to other documents of interest to the investigation which are also consulted.
Deployable structures. Clasification
Historically we have attempted to classify the different systems of deployable structures identifying connections among the different families through their mechanical and structural behavior (Fenci et al., 2017). These are criteria that have been established by recognized authors throughout history. The aim of this section is to provide a theoretical framework for the origami method:
a) Merchan (1987) bases his classification on the differentiation between member structures and those based on surfaces, also seeking disparity in the distribution of loads.
b) Gantes (1991) distinguishes deployable structures according to the application environment; they can be terrestrial or spatial.
c) Pellegrino (2001) starts from the kinetic perspective to carry out the classification, specifies certain structures through clear examples, but does not delve into all of them, leaving aside some such as those based on the concept of tensegrity.
d) Hanaor and Levy (2001) make a two-way distinction: morphological and kinematic.
e) Korkmaz (2004) starts from the point of view of architecture, and distinguishes between deployable buildings and constructions formed by deployable parts, between building and component.
f) Schaeffer and Vogt (2010) differentiate between movement in rigid materials and deformable materials.
g) Stevenson (2011) continues with the conception of Korkmaz and develops it. Based on the morphology of the material difference between physical transformation and position in space and the direction of transformation.
h) Del Grosso and Basso (2013) difference between deformable structures and structures with rigid joints, following the current of Hanaor and Levy.
i) Rivas Adrover (2015) considers two main aspects, the one based on structural components and the one that is inspired by other sources giving rise to certain generative techniques.
Based on this, the differentiation continues, in the first case according to the flexibility of the material and in the second one, based on the source of inspiration.
According to the latter classification, origami, the main object of interest for the present study, is considered a generative technique. It is a system that, despite not having its origin in the structural design, has qualities that make it intuitively optimal when solving deployable.
Origami
The origami method was born in Japan around VIII B.C., after the paper of Chinese origin arrived on this island via Korea. It consists of the transformation by folds, from a sheet of flat paper into sculptural forms, a transition is given between the two and the three dimensions without adding more elements than bending operations.
In the beginning, the folds contained a certain symbolic meaning, but the ceremonial perspective disappears over time, and origami becomes a technique at the service of decorative art, linked to the creation of toys and inexpensive pieces.
It was in the 3rd century A.D. when Akira Yoshizawa developed this art. He worked with a special paper that allowed him to generate thousands of new figures and he was the first one to use the wet paper technique. It established a code based on dashed lines and arrows that enable the disclosure of their discoveries, allowing the evolution of the method.
Origami, as a trend, resurrects in the nineties of our era with the socalled ”Bug Wars”. Figures become more complex when it is decided to apply mathematical knowledge to the design of fold patterns (Haven, 2014).
Below there is a tour of different authors who have tested this union obtaining revealing results for fields as far a priori as medicine and aerospace engineering.
Robert Lang
Robert Lang is an artist and author of the ”Tree Theory” algorithm capable of solving by means of the tree concept any desired shape, available through the ”TreeMaker” program.
This program generates a base plane with axes of the desired length, which later can be folded to form the origami figure, it is the tree-shaped pattern. It is based on the theory that each geometric tree is the projection of a uniaxial base. The folding time has as variables the number of crests, vertices, or issues such as symmetry or how modular the object can be (Haven, 2014).
He proposes the application of this system to so-called mechanical metamaterials, those that could not exist otherwise than folded. Given that, most of the buildings built today are the result of industrial manufacturing, any innovation in this sense is of direct application to architecture.
Tomohiro Tachi
Tomohiro Tachi studies the behavior of so-called rigid origami, a system of surfaces developed by sections convertible into a mechanism if the faces and folds are replaced by panels and hinges. This is of great interest for architecture since (Tachi, 2010):
a) If the airtightness of the structure is achieved, a space can be enveloped and developed, either through the façade, the roof, or both.
b) By not relying on the elasticity of the materials, it is possible to generate kinetic, robust, and large-scale structures.
c) The transformation of the structural complex is under the action of a lower number of degrees of freedom than a traditional structure, so that it is possible to achieve a semi-automatic actuation of the whole.
However, the direct application of these patterns to the architecture is not feasible fundamentally due to the change of thickness that occurs when we move from the paper model to the constructive reality.
Tachi offers two different solutions to solve this scale problem:
a) The first solution is based on the sharp panel method. To avoid the collision between faces when folding the structure, the facets are sharpened balancing the thickness in the directions of the folds. By setting the useful angles during the deployment motion, the structure works for certain dimensions.
b) The second solution, simpler at the time of manufacture, involves working with two different thicknesses, one for the interference area between planes (the one that according to the previous solution would sharpen) and another for the central area of the faces. This solution generates hollow areas at the vertices that prevent the tightness of the assembly.
Starting from both systems, the folds can be resolved through embedded hinges or textile materials.
The author develops a computer application that allows constant section designs to be carried out through the Grasshopper program that works as a plug-in in Rhinoceros. He also develops a series of prototypes in which it implements its research:
•Rigid/foldable thick origami (Tachi, 2011): Prototype corresponding to the second method of solving the scale problem, constant thickness panels. For the built example, hingefree joints are proposed, based on the superimposition of flexible materials: cardboard, fabric + cardboard.
•Rigid origami with Vacuumatics (Rivas-Adrover, 2015): This other prototype raises the possibility of using Vacuumatics technology in the joints. This technique allows to add rigidity to the set in the desired positions thanks to the extraction of air.
•Rigid/flexible composite curve origami structure: Prototype based on a concept further from the art of traditional origami. Seeking to solve the thickness conflict, the author changes the point of view and approaches the exercise of curved folding. This simplifies the number of fold lines and with it, their manufacture. From a smooth curve, surfaces are created that form a family of structures able to bend and unfold without losingrigidity. These structures can be combined with each other, in the case of the dome-shaped model generated from eight cylindrical elements welded together by smooth sheets.
Eric Demaine
Eric Demaine works in the field of computational origami. It is a line of research that has to do with the interests exposed by Tomohiro Tachi (Vives, 2015) to analyze the system and find the rules that configure it to be able to dispose of it in previously unsolvable situations.
He puts forward a technique designed to solve origami with thickness that consists of accommodating the panels with the double hinge technique, according to which each fold is divided into two. As Tachi does, thickness is eliminated in the folding area, but in this case, it is done by duplicating the mechanism, which generates difficulties in complex structures.
Together with Tomohiro Tachi, he creates the computer program ”Origamizer” that generates crease patterns for any given mesh.
Biruta Kresling
The so-called Kresling pattern is the result of wrinkling a sheet of paper around two coaxial stems with a gap between them. Turning them in opposite directions on their common axis, a regular pattern is generated and the cylindrical wall collapses forming a kind of diagram.
This is an almost accidental, experimental discovery, but the test of time has allowed us to find a relationship between the height of the gap and the angles of passage, the number of parallelograms that are formed. In this way, the pattern can be used in design tasks of reconfigurable structures. Interestingly, this system that has been reached through the folding of paper is present in nature and could be classified as typical of the biomimetic generative technique (Kresling, 2020).
Katia Bertoldi
Katia Bertoldi develops, based on the origami code, a robust design strategy based on the tiling of polyhedral that fill the space to create reconfigurable structures, periodic sets of rigid plates and elastic hinges (Overvelde et al., 2017).
In this case, the possibility of not building the whole on a single plane is assumed. A combination of elements that do have their origin in the origami method is then carried out. This point is interesting given that other systems such as rigid origami that are born of the ideal situation of a plane in two dimensions, when they are built and according to what scale, lose this essence of material continuity.
Katia’s strategy is similar to that of other disciplines like traditional apparel. In most cases, folding operations are combined with other types of joints, thus achieving versatile structures. There is even a current of traditional origami called ”modular origami” that consists of combining several identical pieces together to form a complete model. In this way, complex parts can be reached from simple elements.
The result is application for the construction of metamaterials whose modularity is adaptable to different projects, allowing a unique manufacturing process to be applied in very different situations.
In addition, her team has been able to generate an algorithm available for free in Matlab.
Esther Rivas-Adrover
Adrover detects the problem of thickness of origami structures when moving from the ideal paper model to the building scale.
So far, the methods used to avoid the problem of the thickness between panels, the collapse of the faces at the time of the fold had been the following (Rivas-Adrover, 2018):
a) Tachi Tomohiro, as already seen, proposes to reduce the thickness in the folding areas.
b) Edmondson proposes to create compensation panels away from the folding area. While Tomohiro solves the problem by subtraction, Edmondson does so by addition. Both strategies have the problem of creating discontinuous and unsightly surfaces.
c) Temmerman considers the possibility of avoiding vertices in the models, creating gaps in such encounters, such a solution generates problems of tightness, transferring the problem to later phases.
d) Chen provides a thick origami method based on mechanical theories that dispense with the ideal zero-thickness model, but this, while interesting as a solution, is not effective in all cases.
Rivas-Adrover proposes to generate folding structures with scissor type hinges, this solution involves adding a degree of freedom to the initial structure which allows to generate structures that in addition to folding and unfolding can contract and expand.
The author, as seen in many other cases, develops an algorithmic method called ”Form Generation Method of Relative Ratios” (FGMORR). In the following example he develops his application and compares the result with the method explained by Chen.
A prototype is generated in which each face of the Chen model is replaced by a succession of 77 bars and 124 nodes, reproducing the original six faces, a model with 462 bars and 744 nodes is obtained, for its construction only 6 different types of bars are used. The folds are located on the same spatial line for both cases. The coplanar bars are joined by pivots, in the rest of the cases they did it by means of elastic knots capable of allowing small margins of deformation. The maximum gap between the position of the nodes in the theoretical model and the constructed one is 1.5 mm; its disposition is studied so that these discrepancies are annulled among themselves. The images show the possibility of contraction and expansion that the Rivas-Adrover model offers at any stage of folding or unfolding the origami model.
Rivas-Adrover establishes a series of conditions that allow applying the FGMORR method to thick origami:
a) Thick origami must be made of equal or proportional thicknesses so that when translating the geometry, the final nodes match.
b) The patterns that mark the folds and join faces together must have an equal morphology and bilateral symmetry.
The application of this method can be carried out through the Grasshoper program which, in turn, operates in Rinhoceros.
The importance of this strategy lies above all in the ability to modify the volume of objects and thus the shape. As in the case of Katia Bertoldi’s research, the results are constructions of variable form, versatile and with revolutionary possibilities at the time of applying them to the architectural project.
In any case, Esther’s work could function as a structural component of the building and requires a protective, enveloping layer to be completed as a habitable construction, this functional division implies the need to create a closure capable of adapting to the volumetric flexibility offered by the structure. On the other hand, the investigations with hinges of scissors have been reason of interest by some professionals of the Spanish architecture. Authors, who, undoubtedly, Rivas-Adrover, has considered when developing their studies and who, classifies in the section combined structural components (Rivas-Adrover, 2015).
Examples of built arquitecture

Before drawing conclusions about the application of the origami method to the architectural project, it is necessary to investigate examples carried out that help establish a realistic practical basis. For this purpose, we present some case studies cited by Rivas-Adrover and framed in its, already cited, classification.
Combined structural components
a) Itinerant theatre 1961/ Emilio Pérez Piñero (Figure 1): The work arose in the 1960s in response to a competition of ideas proposed by the International Association of Architects, in which Buckminster Fuller, Félix Candela and Over Arup appear as judges.
The structure, which covered 8,000 square meters and weighed 40 tons, consisted of the assembly of three-arm scissor bars bolted in coplanar positions. A canvas was used to cover it, the size of which was adapted to the size of the theatre. The following images show the volumetric difference reached between the folded and unfolded structure, relevant to the itinerant character of the object.
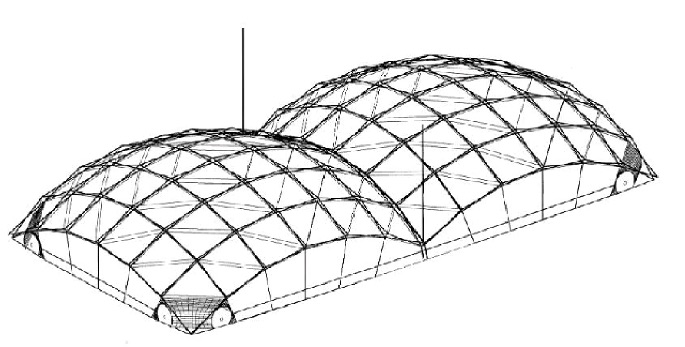
b) Indoor pool San Pablo roof 1996/ Escrig, Valcárcel, Sánchez (Figure 2): Built almost 40 years later by the architects Félix Escrig, Juan Pérez Valcárcel and José Sánchez, the cover of the pool of San Pablo makes possible the presentation of the covered or uncovered pool depending on the weather, and without leaving any trace of the structure.
For this, its creators design a structure based on modules of type X-Frame that are moved by crane to the place of implantation. From their initial position and with the help of gravity, they are deployed to anchor to foundations and reinforcements, disassembly is equally simple.
Each joint connects 4 bars of equal measure, without the need for node offset. The problem of the envelope is also solved in this case, by hanging the fabric at the lowest level of the structure and anchoring it to the different quadrilaterals.
Generative technique, origami
This section of the classification is considerable from a strict point of view in the present study, which starts from origami as a way of approaching the design of folding structures. It clarifies how origami excludes gluing and cutting operations from its method, becoming part of the studies of ”paper folds”. The latter began at the Bauhaus school at the direction of Josef Albers. The starting point refers to the famous ancient structure of the MiuraOri, on which some of the systems we will see below are based.
a) Pavilion of Venezuela Expo Seville 1992/Zalewski and Hernández: This deployable structure works in a single direction and is based on a rectangular pattern divided into nine sections. The combination of this type of surface together with the one that defines the structural pattern of the already mentioned cover of San Pablo makes possible the study of unfoldable structures with two-way folds by Maciej Piekarsi. These structures are rigid, foldable and although in principle they are established as planarians, they can become curves at the time when the angles of the modules are modified.
There are more examples of the application of the origami method to architecture, some of them relevant when telling the history of art. Below, several of these projects fit into a personal classification adapted to architectural design concepts.
b) Structures based on the origamideployable concept:

•Dymaxion Deployment Unit, 1939. Buckminster Fuller (Figure 3). It is a milestone in the history of architecture, this model of prefabricated house used during the war had a dome formed by sheets arranged radially, able to be collected with a single movement.

•Tricycle House, Beijing 2012, People Architecture Office (Figure 4): This portable housing is designed on the occasion of the exhibition Get It Louder. It is experimented with polypropylene, as a material that can be folded and welded without the aid of hinges or intermediate elements, making use of the ideal model of 0 thickness that offers a pattern formed by parallel folds of valley and mountain with three vertices in ”V” in the longitudinal direction. The result is a house that can be carried in tow and that increases and decreases in volume like an accordion.
c) Structures based on the concept of origami-rigid:
•UNESCO Headquarters. Paris 1958. Pier Luigi Nervi (Figure 5): This building is based on the principle of folded laminar structures. It is one of the first buildings that contemplates the use of this system of concreting. The fold is in a single direction has a structural reason, providing rigidity to the building.
•Sulphur factory shelter Pomezia, 1966. Renzo Piano (Figure 6): The design of this vaulted structure meets specific lighting, chemical and spatial requirements. To solve the problem, Piano formulates a structural system of fiberglass panels folded and joined together as would the faces of a folded paper vault. The result is a rigid structure which allows the illumination of the outer space and does not degrade before the fumes generated in the extraction of sulphur.
d) Structures based on the formalist conception of origami: Buildings that use the language of origami to create a space type, vibrant and contemporary, but for which the method lacks structural function or versatility through deployment or volumetric variation:
•Seattle Library, 2004. LMN, OMA: In this work they use the language of folds to sew a set of plants not coincident in height, and that owe their outdated location in the horizontal axes to functional issues. The folds help to make the building a good example of contextual architecture, as they sculpt the elevations and views in relation to the buildings of its immediate surroundings.

•Medialab Prado, 2008. Langarita Navarro (Figure 7): Expansion of the old Belgian Sawmill, which seeks to update the pre-existing building and adapt it to the new functions of the building. The aesthetic strategy involves constructing a new and differentiated element of reinforced concrete construction. For this, the architecture study is based on the language of origami reaching a result of pretechnological appearance. But this appearance does not respond to a need to give structural rigidity. In fact, the main structure is composed of a series of metal frames. Nor is it a building that can be transformed into volumetric or folding. Nevertheless, the image generates in the vieweruser that sense of dynamism, making them believe that the whole can undergo formal modifications at any time.

•Congress Hall and Auditorium, Plasencia, 2017. Selgascano (Figure 8): This example has much to do with the previous one. A folding language is used to detach itself from the existing constructions and rest on the natural terrain. The authors justify the formal decision taken as a result of the expression in section of the stage area. But this clearly contains an intention of pseudo transformable architecture (because it does not allow dynamic alterations) whose generative technique would describe Rivas-Adrover as Biomimetics.
Conclusion
One of the first conclusions that are obtained in view of this study is that the main difficulty presented when building with origami techniques is the transition from the ideal model with zero thickness to the building reality. A problem, on the other hand, with which every designer must deal, is to design to manufacture, but in this case, it becomes central from the moment of the initial design.
In view of the data collected, it is conceivable that rigid origami, composed of a sequence of folded faces, is useful when manufacturing components for construction, providing rigidity to materials that, a priori, lack it. But when it increases in scale, the system generates more conflicts than opportunities, saving paradigmatic situations in which the origami code offers an optimal response to a specific case of design. Two main strategies then emerge:
a) Dividing the structure from its envelope.
b) Combining the folding with other types of joints.
The result of combining both strategies leads us to the bar and knot structures employed since the time of Buckminster Fuller. They are systems that, based on the classification presented by RivasAdrover, the guiding thread of this study would no longer be part of the origami generative technique.
Moreover, in view of the studies presented here, there is another strategy of the origami method based on modular origami and which uses the repetition of parts designed through this generative technique to obtain rigid and/or deployable assemblies.
Contributions
The present study could serve as a starting point for different areas of research:
a) The study of a classification specifically focused on the design strategies offered by the origami method. This should consider issues such as the timing of the code and how this temporary issue affects in constructive terms. Whether it is a question of language (appearance), conceptual (bar structure) or surfaces (rigid origami). If applied to the assembly, modularly or to some of its components (materials). And whether the function of origami is to generate a shape, to provide rigidity, or to give rise to a deployable structure.
b) The application of the theoretical studies exposed for the creation of new metamaterials, modular, but with greater possibilities of adaptation to the constructive realities. That allow an optimal level of industrialization of the architectural project without, therefore, having to flee from the formal, contextual, and culturally responsible investigation of the architecture. The Kresling pattern is a new way to compact cylindrical wall structures while maintaining rigidity.
c) Katia Bertoldi systems are highly reconfigurable, this can be useful even from a sustainable point of view, by allowing the transport of large volumes in small spaces.
d) Optimize paradigmatic designs such as the Tricycle House, seeking to solve the construction of buildings for emergency situations, as has already been done with other methods such as air structures, but avoiding the energy expenditure that these involve.
References
Fenci, G. and Currie, N., (2017). Deployable structures classification: A review. International Journal of Space Structures, 32(2), pp. 112-130.
Haven, O. (2014). Paper Perfect. Robert Lang and the Science of Origami. The Virginia Quarterly Review, 90(3), pp. 12-19.
Kresling, B., (2020). The fifth fold: Complex symmetries in Kresling-origami patterns. Symmetry: Culture and Science, 31(4), pp. 403-416.
Overvelde, J., Weaver, J., Hoberman, C. and Bertoldi, K., (2017). Rational design of reconfigurable prismatic architected materials. Nature, 541 (7637), pp. 347-352.
Rivas-Adrover, E. (2015). Estructuras desplegables. Arquitectura, ingeniería y diseño. Promopress
Rivas-Adrover, E. (2018). Origami-Scissor hinged geometry method. Origami 7.
Tachi, T. (2010). Geometric Considerations for the Design of Rigid Origami Structures. Proceedings of the International Association for Shell and Spatial Structures (IASS), 12, pp. 458-460.
Tachi, T. (2011). Rigid-Foldable Thick Origami. Origami 5, pp. 253-263.
Vives, F. (2015). El código origami (Película). Francia: La Compagnie des Taxis-Brousse.
Image credits
Article opening image. Available from: https:// www.grasshopper3d.com/photo/folding-of-thickrigid-origami?context=user
Figure 1. Available from: https://arquiscopio.com/ las-estructuras-desplegaples-de-perez-pinero/
Figure 2. Escrig, Félix, Pérez V., Juan, Sánchez S., José, (1996). Las cubiertas desplegables de malla cuadrangular. Bac Boletín Académico Revista de investigación y arquitectura contemporánea
Figure 3. Available from: https://www.moma. org/calendar/exhibitions/3015/installation_ images/34537
Figure 4. Available from: https://www. designboom.com/design/tricycle-house-andgarden-by-peoples-architecture-office/
Figure 5. Available from: https:// es.wikiarquitectura.com/edificio/sede-la-unescoparis/
Figure 6. Trautz, Martin., Herkrath, Ralf, (2009). The application of folded plate principles on spatial structures with regular, irregular and free-form geometries. Proceedings of the International Association for Shell and Spatial Structures (IASS) 2009, Valencia
Figure 7. Available from: https://afasiaarchzine. com/2014/06/langaritanavarro-arquitectos/
Figure 8. Available from: https://www.floornature. es/selgascano-palacio-de-congresos-y-auditorioen-plasencia-14461/